Desarrollo de un Pipeline y visualizaciónes para datos de ventas de un comercio de productos deportivos
Contenido Link to heading
Resumen del Proyecto Link to heading
Este proyecto implementa un pipeline robusto de ELT (Extract, Load, Transform) para analizar datos de ventas de un comercio de productos deportivos. El pipeline ingresa datos brutos en formato Excel a un almacen de datos en PostgreSQL, transforma los datos para análisis y visualiza los resultados utilizando Power BI y Looker. Sin embargo, como el análisis no es el enfoque principal de este proyecto, los dashboards son simples y sirven para demostrar la funcionalidad end-to-end del pipeline.
El codigo de este proyecto se puede encontrar en Github, da click en el siguiente enlace: GitHub Link to heading
Fuente de Datos Link to heading
El dataset utilizado es el Sport Products Sales Analysis Challenge de FP20 Analytics Challenges Group, una comunidad de LinkedIn enfocada en proyectos de análisis de datos. Puedes encontrar más sobre ellos aquí.
Después de examinar todos los datasets que han compartido, seleccioné este porque ofrece un conjunto rico de dimensiones, incluyendo Tiempo (Fecha de Factura), Geografía (Región, Estado, Ciudad), Jerarquía de Productos (Producto), y Entidades de Negocio (Retailer, Sales Method), lo que lo hace perfecto para el análisis. Además, el dataset presenta desafíos reales de calidad de datos, como manejar errores tipográficos y estandarizar nombres de columnas, lo que lo hace excelente para practicar la lógica de transformación.
Arquitectura del Sistema Link to heading
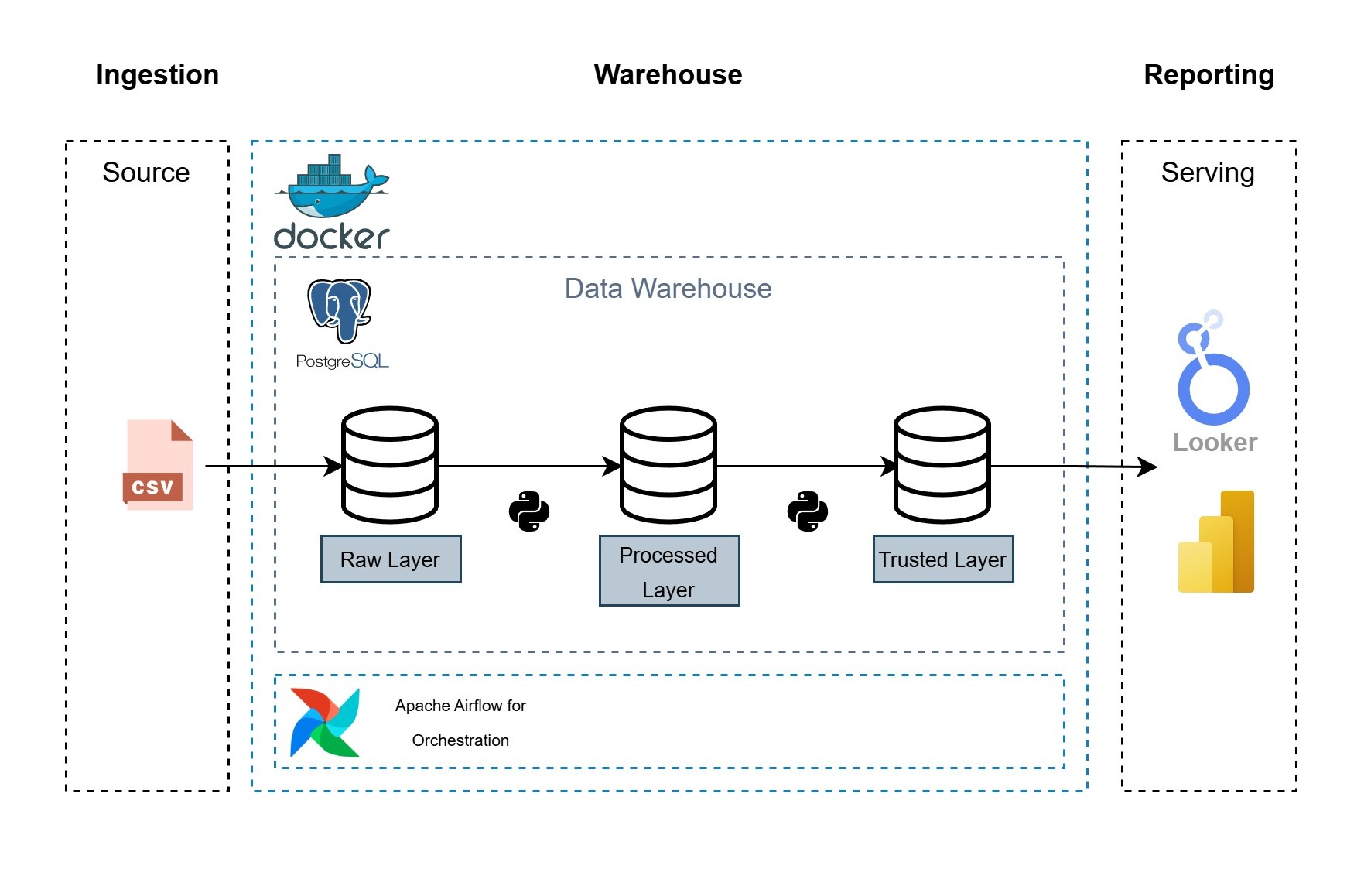
El proyecto utiliza una arquitectura moderna basada en contenedores:
- Orquestación (Airflow): Gestiona el flujo de trabajo ELT.
- Extracción: Recupera datos de fuentes externas.
- Carga: Ingesta datos crudos a PostgreSQL (schema: raw).
- Almacenamiento (PostgreSQL): Base de datos relacional con esquema en capas (Raw -> Processed -> Trusted).
- Transformación: Limpieza y normalización de datos mediante SQL (schema: processed).
- Modelado: Creación de vistas analíticas (schema: trusted).
- Visualización (Looker/Power BI): Herramientas de visualización de datos que consumen las vistas confiables para mostrar KPIs y gráficos.
- Infraestructura (Docker): Todo el entorno se despliega mediante docker-compose.
Dashboards Link to heading
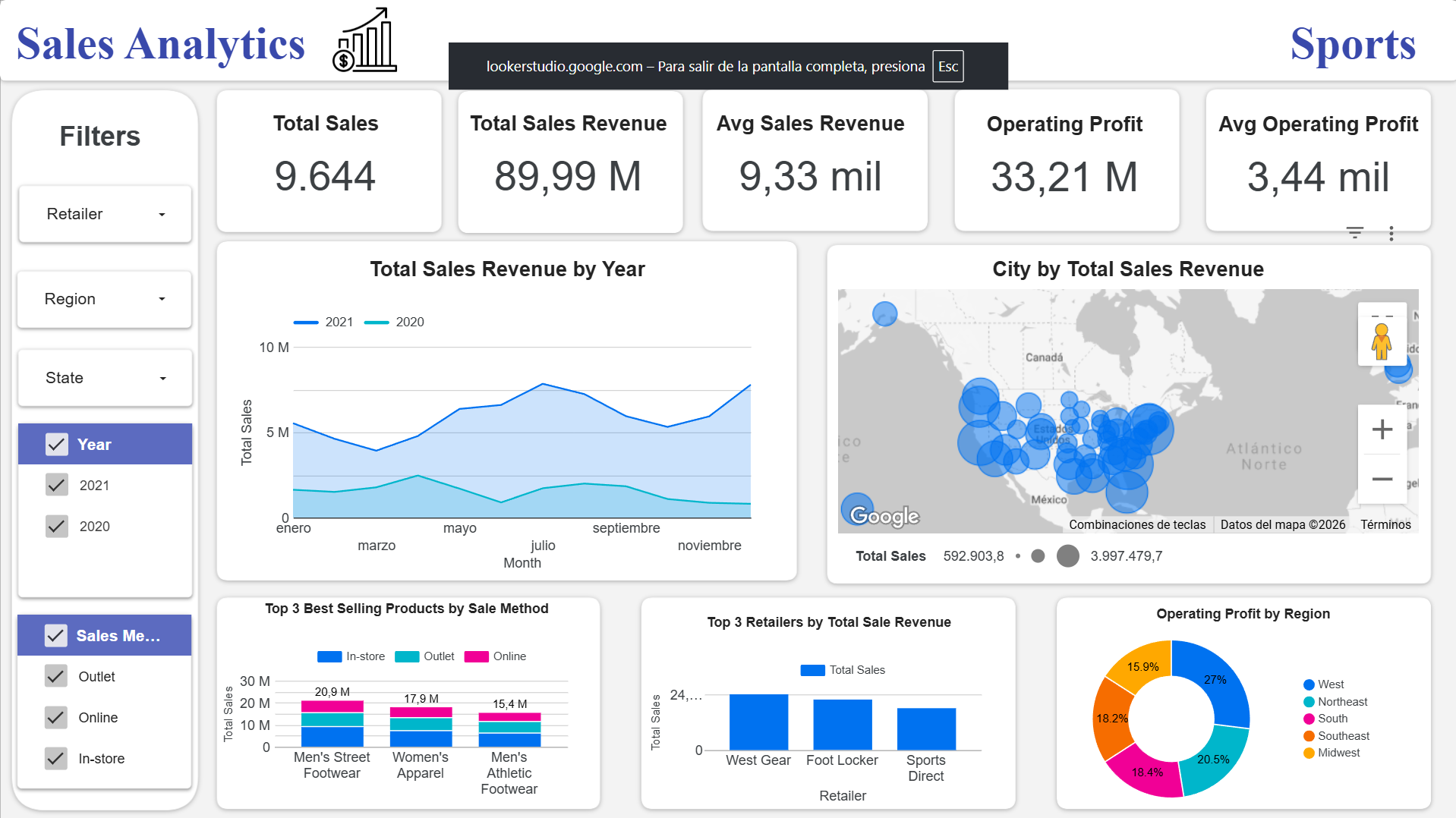
Este Dashboard fue creado usando Looker:
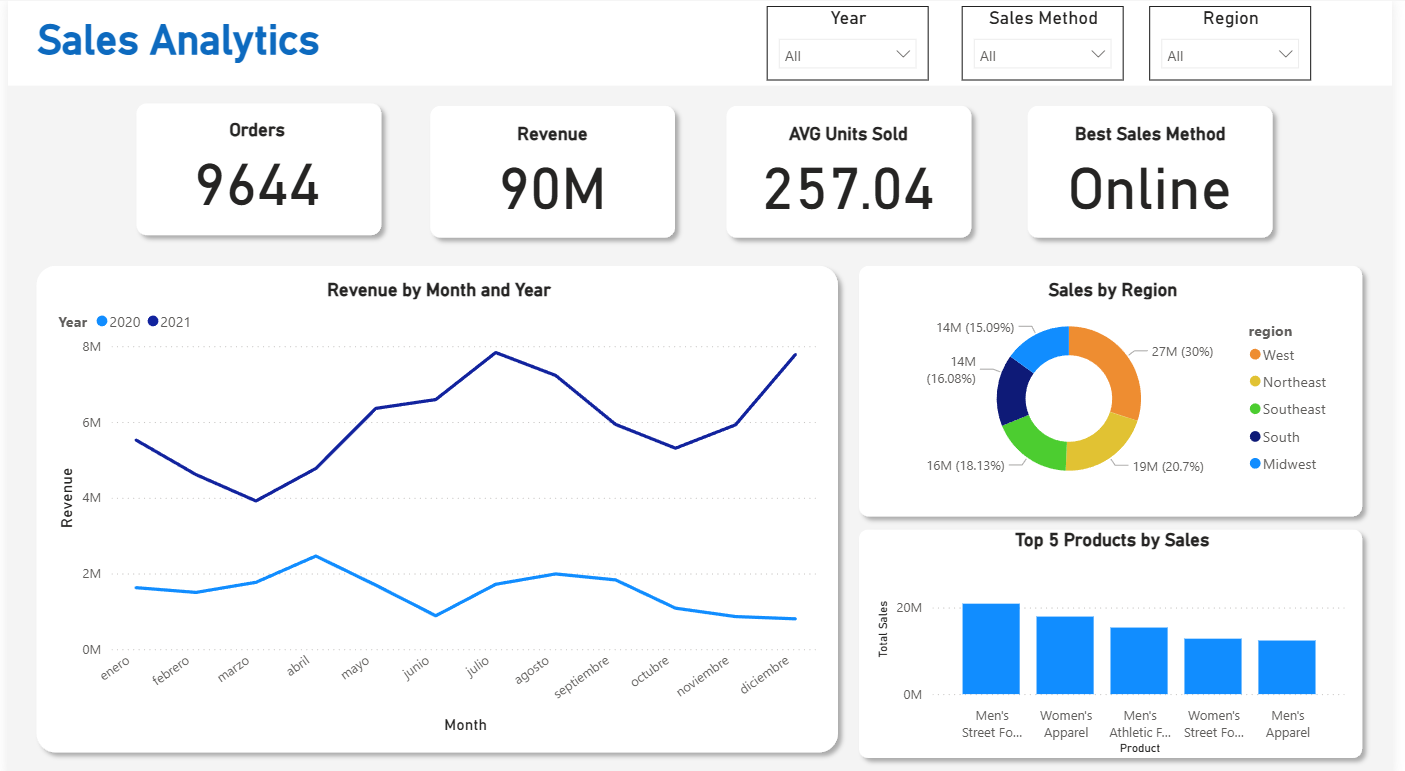
Este Dashboard fue creado usando Power BI:
Tecnologías Utilizadas Link to heading
- Python: Utilizado para la extracción, transformación y carga de datos.
- Airflow: Utilizado para la orquestación del pipeline.
- Docker: Utilizado para la orquestación del pipeline.
- PostgreSQL: Utilizado como almacenamiento de datos.
- Power BI: Utilizado para la visualización de datos.
- Looker: Utilizado para la visualización de datos.