Pipeline para análisis de desapariciones infantiles en Chiapas (México)
Contenido Link to heading
Resumen del Proyecto Link to heading
Este proyecto implementa un pipeline ELT (Extract, Load and Transform) completo y un dashboard interactivo para analizar datos sobre desapariciones de niños, niñas y adolescentes en Chiapas, México. El sistema está contenerizado utilizando Docker y orquestado mediante Apache Airflow, con PostgreSQL como base de datos y Flask para la visualización.
El codigo de este proyecto se puede encontrar en Github, da click en el siguiente enlace: GitHub Link to heading
Contexto del Dataset Link to heading
El dataset proviene de la plataforma datamx. Especificamente, el dataset usado es DESAPARICIÓN DE NIÑAS, NIÑOS Y ADOLESCENTES EN CHIAPAS 2019-2025.
Relevancia Social Link to heading
Este dataset es de crítica importancia social y humanitaria. La desaparición de menores es una crisis que afecta profundamente el tejido social, la seguridad y los derechos humanos fundamentales. Contar con datos estructurados y accesibles es el primer paso para visibilizar la magnitud del problema y movilizar recursos de manera efectiva.
Problema a Resolver Link to heading
El análisis de estos datos permite abordar la falta de información centralizada y procesable. Al identificar patrones, como los municipios con mayor incidencia, los grupos etarios más vulnerables o las tendencias temporales, se pueden diseñar estrategias de prevención más efectivas y optimizar los esfuerzos de búsqueda y localización.
Arquitectura del Proyecto Link to heading
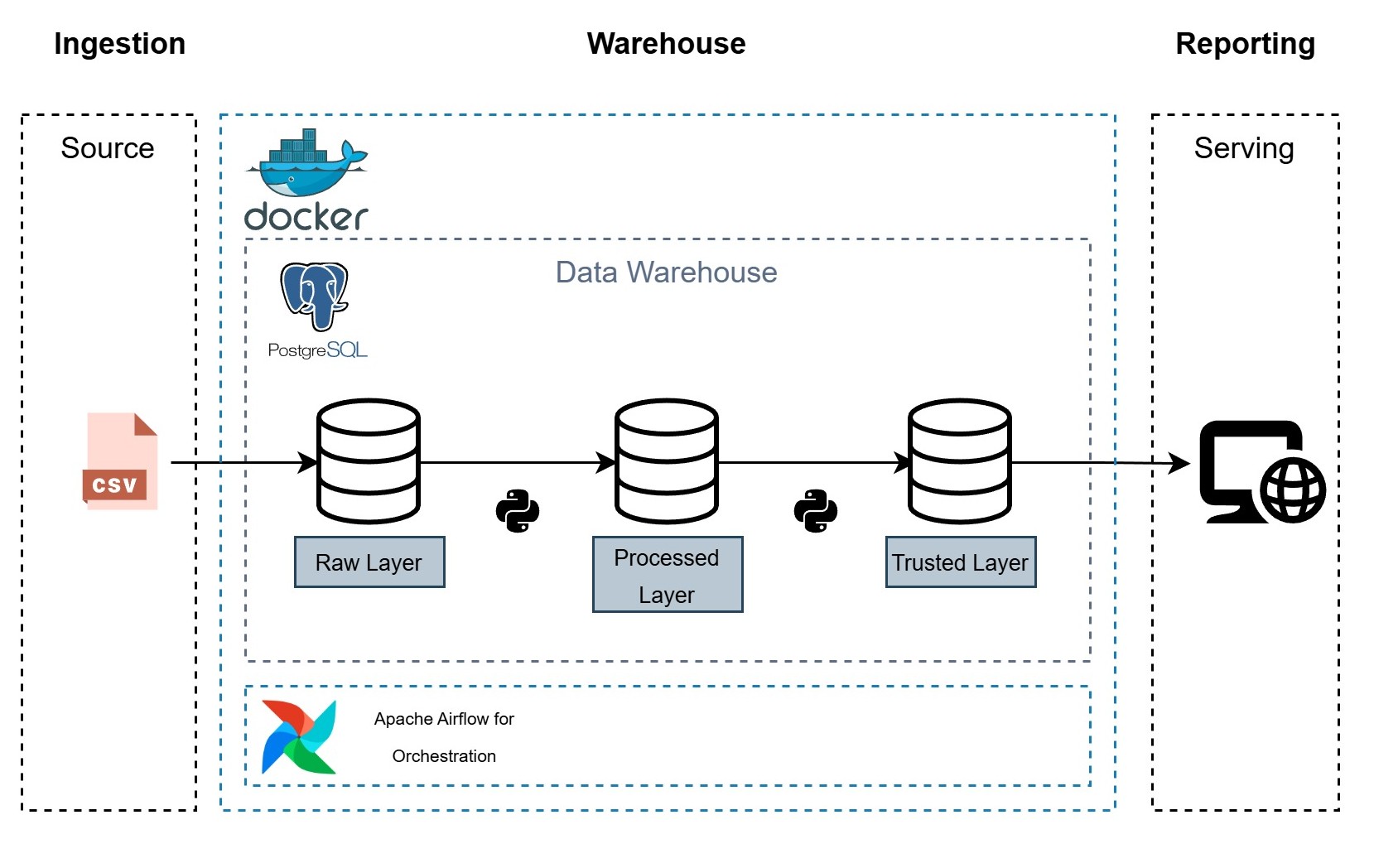
El proyecto utiliza una arquitectura moderna basada en contenedores:
- Orquestación (Apache Airflow): Gestiona el flujo de trabajo ETL.
- Sensor: Detecta la llegada de nuevos archivos de datos.
- Preparación: Prepara los datos para ser cargados. Pequeña transformación.
- Carga: Ingesta datos crudos CSV a PostgreSQL (
schema: raw). - Transformación: Limpieza y normalización de datos mediante SQL (
schema: processed). - Modelado: Creación de vistas analíticas (
schema: trusted). - Permisos: Gestión automática de roles de base de datos para seguridad.
- Almacenamiento (PostgreSQL): Base de datos relacional con esquema en capas (Raw -> Processed -> Trusted).
- Visualización (Flask + Chart.js): Dashboard web que consume las vistas confiables para mostrar KPIs y gráficos en tiempo real.
- Infraestructura (Docker): Todo el entorno se despliega mediante
docker-compose.
Dashboard Link to heading
Debajo se muestra el dashboard resultante. Un dashboard sencillo que muestra KPIs relevantes y gráficos para explorar los datos.
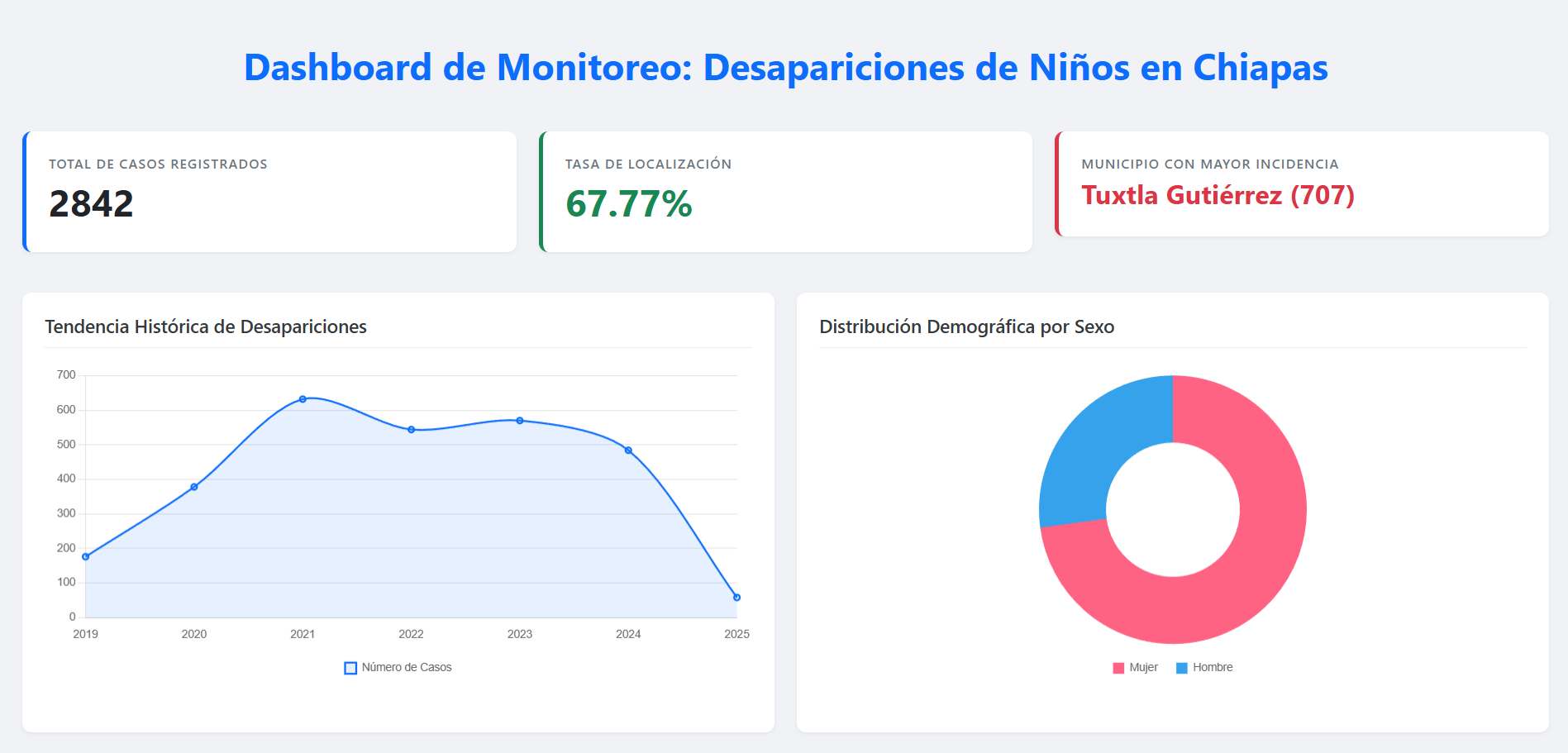
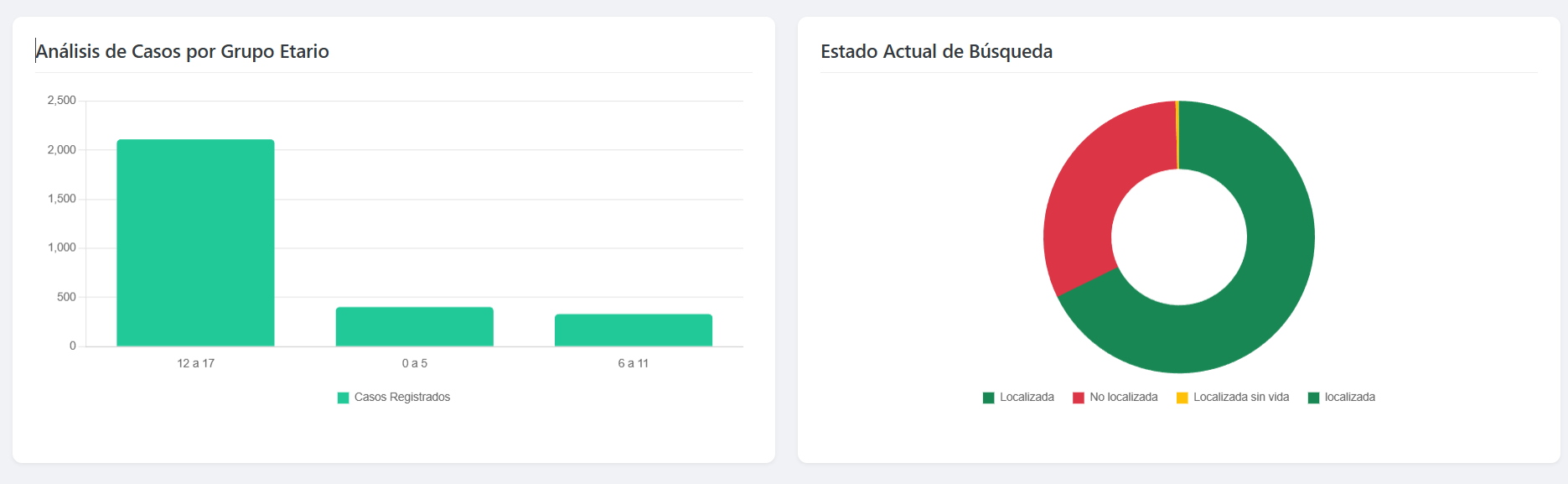
Entre las principales conclusiones se encuentran:
Tecnologías Utilizadas Link to heading
- Python
- Apache Airflow
- PostgreSQL
- Flask
- Chart.js
- Docker