End-to-End Pipeline para registros de niños desaparecidos
Contenido Link to heading
- Objetivo del Proyecto
- Descripción del Conjunto de Datos
- Flujo del Pipeline
- Resultados
- Tecnologías Utilizadas
Objetivo del Proyecto Link to heading
Desarrollo de un Pipeline serverless y orientado a eventos en AWS y Snowflake que ingesta archivos CSV sobre personas desaparecidas en Chiapas, México, valida la calidad de los datos, transforma los registros a Parquet particionado, carga los conjuntos curados en Snowflake y usa dbt para construir la capa analítica para su visualización en Power BI o QuickSight. Además, se usa Terraform para el aprovisionamiento y gestión de todos los recursos de AWS.
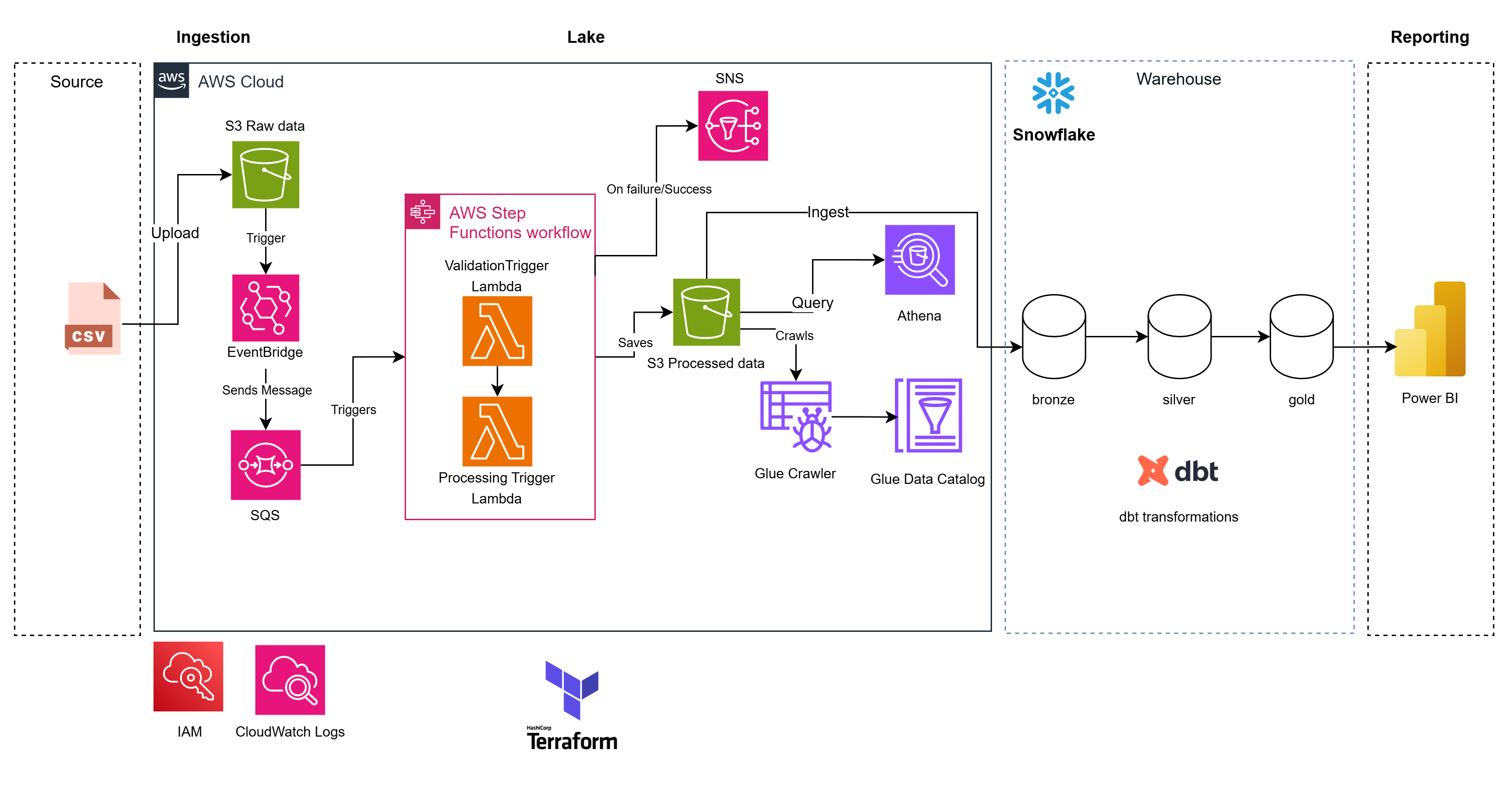 Figura 1. Arquitectura serverless y flujo de datos.
Figura 1. Arquitectura serverless y flujo de datos.
Puedes encontrar el código de este proyecto en GitHub. Link to heading
Descripción del Conjunto de Datos Link to heading
El conjunto de datos fuente es un CSV (por ejemplo, base-desapariciones-dataton-2025.csv) con registros de niñas y niños desaparecidos en Chiapas entre 2019 y 2025. Incluye campos como sexo, edad, grupo etario, municipio, región, colonia/localidad, condición migrante, fecha de desaparición, día de la semana, horario, estatus del caso y días sin localizar.
Flujo del Pipeline Link to heading
- Los CSV se cargan a
raw/en un bucket de S3. - EventBridge activa un tópico SNS que publica hacia SQS.
- Un Lambda inicial dispara un flujo en AWS Step Functions.
- El Lambda validador revisa columnas requeridas y un umbral de calidad (>70% filas válidas).
- El Lambda transformador limpia campos (fechas, edades, horarios, división de ubicación) y escribe Parquet particionado (
year=YYYY) en el bucket procesado. - Un cargador de Snowflake ingesta los archivos parquet procesados en Snowflake para analítica posterior.
- dbt modela y prueba la capa analítica sobre Snowflake para generar marts listos para BI.
- Glue Crawler actualiza el catálogo para consultas en Athena, y los fallos se envían a un DLQ y generan alertas con CloudWatch/SNS.
Resultados Link to heading
Los datos procesados se consultan en Athena y Snowflake, y se conectan a Power BI o QuickSight para construir tableros que muestran tendencias por municipio, grupo etario, periodo y estatus del caso. dbt aporta el modelado dimensional y la consistencia de la capa analítica.
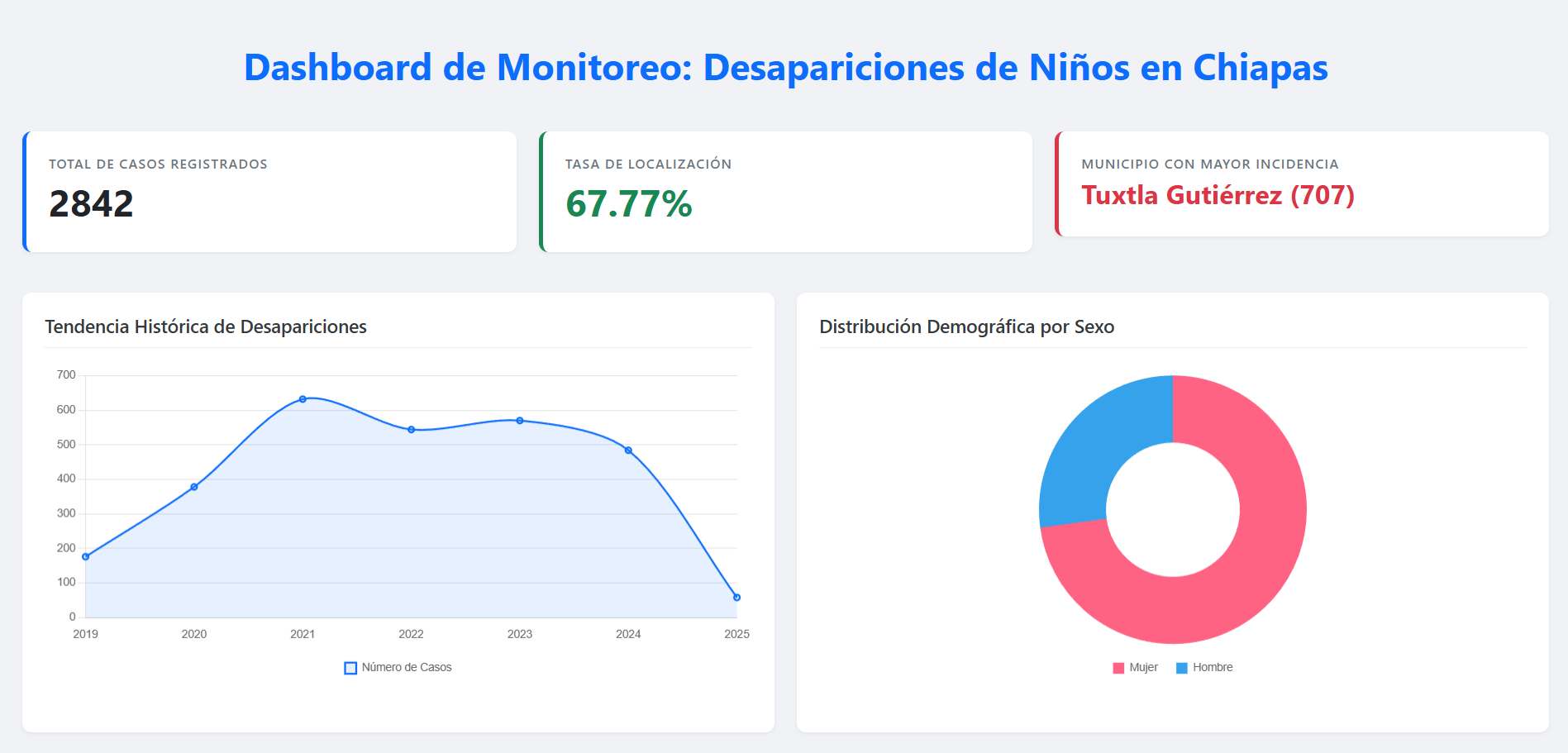 Figura 2. Ejemplo de Dashboard en Power BI.
Figura 2. Ejemplo de Dashboard en Power BI.
Tecnologías Utilizadas Link to heading
- AWS S3, EventBridge, SNS, SQS
- AWS Lambda, Step Functions
- AWS Glue, Athena
- Snowflake, dbt
- Terraform
- Python, pandas, awswrangler
- Power BI